项目背景
本项目旨在探索如何使用卷积神经网络(ResNet)提取图像空间特征,并结合LSTM对时序依赖进行建模,从而预测车辆在自动驾驶中的转向角度。
此任务属于端到端自动驾驶建模的一部分,重点在于将连续图像帧映射为连续控制输出(方向盘角度)。
模型结构概览
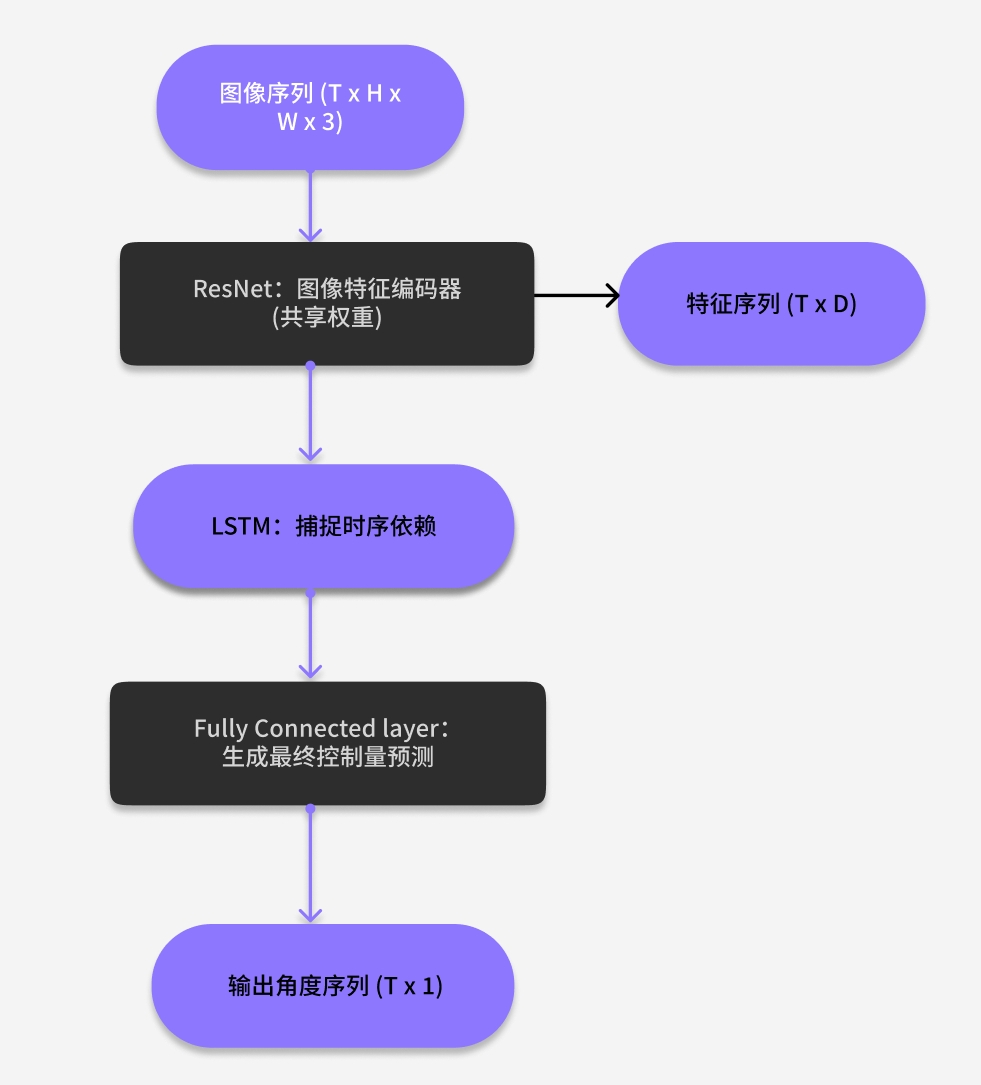
整体结构采用两阶段:
- ResNet 特征提取:对每帧输入图像进行空间编码,提取每一帧的空间语义信息,如车道线、前车位置等。
- LSTM 序列建模:将序列化的图像特征送入LSTM,实现对短期历史状态的记忆和对当前状态的连续预测,预测未来1~N帧的角度
模型结构图
数据与预处理
数据来源为模拟驾驶场景中的中心摄像头图像,标签为方向盘角度。
- 输入帧尺寸统一为 224x224
- 标签为每帧角度(可选包含扭矩、车速)
- 图像预处理:resize → normalize → batch
- 标签标准化:使用均值/方差归一化角度值
- 损失函数:MSE 均方误差损失
- 优化器:Adam, 学习率 = 1e-4
- 序列长度:T = 5(即每个样本为连续5帧)
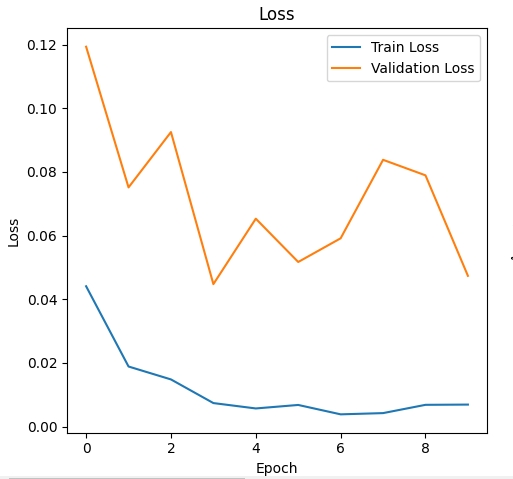
实验结果
在测试集上,MSE 误差为 0.06,对应角度误差约为 7°。
模型在直线段表现稳定,在连续转弯段有一定预测延迟
关键代码片段:
class ResNetLSTMModel(nn.Module):
def __init__(self):
super().__init__()
self.resnet = resnet18(pretrained=True)
self.lstm = nn.LSTM(input_size=512, hidden_size=128, batch_first=True)
self.fc = nn.Linear(128, 1)
def forward(self, x_seq):
batch, seq_len, C, H, W = x_seq.shape
feats = [self.resnet(x_seq[:, i]) for i in range(seq_len)]
feats = torch.stack(feats, dim=1) # [B, T, D]
out, _ = self.lstm(feats)
return self.fc(out[:, -1])
模型选择与对比分析
为什么选择 ResNet 而不是简单 CNN:
预训练权重可加快收敛
ResNet 的残差结构对特征提取更加稳健
为什么用 LSTM 而不是 FC:
能捕捉时间上的上下文依赖
适合处理图像序列任务(比 RNN 收敛更稳定)
我的思考
-
ResNet 有效提取空间特征,但模型在连续转弯区域仍存在滞后。
-
真正部署前还需加入控制平滑性约束、sensor fusion、时延补偿等;
-
若加入车辆状态如速度、上帧角度,效果可能进一步优化。
-
可扩展方向包括: 使用 Transformer 替代 LSTM
引入 attention 模块
增加辅助状态输入(车速、扭矩等)
延伸阅读
下一篇预告:
LSTM在连续控制任务中的优势,以及与Transformer的对比。