理想、小鹏、蔚来的
城市NOA技术战局(上):从BEV到VLA,拆解头部玩家技术路线
主要结论:
继2023–2024年BEV+Transformer+Occupancy Network架构成为智能驾驶的感知主流后,2025年起,行业正加速向更高级的**VLM(Vision-Language Model)与VLA(Vision-Language-Action)**模型演进。相较于传统BEV结构仅关注空间几何关系,VLM/VLA引入语言推理模块,可对标志、规则、指令进行语义理解,结合多模态输入(如摄像头图像、语音交互、交通文本信息),生成更泛化、更类人的行为决策。
芯片与算力能力成为支撑城市NOA架构升级的关键基础。2020年前后主流平台算力集中于144 TOPS,如今已普遍跃升至500 TOPS以上,高端平台如蔚来NX9031、理想Thor-U、小鹏图灵AI芯片等更达到千级算力,支撑端到端推理、大模型部署与多模态处理。自研芯片、自建智算中心、自主模型训练正成为具备战略自主能力车企的核心壁垒。
在感知侧,“视觉为主+激光雷达补盲”已成为当前主流配置。视觉方案具备数据规模与算力适配优势,激光雷达则增强空间精度与安全冗余,尤其在无高精地图场景中具备更强稳定性。不同厂商依据策略选择单感知或多模态融合方案,构建安全容错体系。
- 产品背景
近年来,随着特斯拉AutoPilot不断进阶至FSD,辅助驾驶已从L0级定速巡航,逐步拓展至高速NOA,再迈入城市NOA阶段,覆盖更复杂多变的交通环境。智能驾驶正在从“技术亮点”转向“核心卖点”,显著影响消费者购车决策。
以小鹏和问界为例:小鹏G6智驾版配置占比超过70%,问界新M7的大定用户中也有60%以上选择搭载高阶智能驾驶方案。这一趋势标志着,中国智能驾驶市场已全面进入L2+/NOA功能的规模化普及阶段。
L2+辅助驾驶能力包括自适应巡航(ACC)、车道居中控制(LCC)、自动变道(ALC)、高速NOA等,城市NOA则在此基础上,扩展至非结构化路况中的红绿灯通行、环岛绕行、路口博弈等复杂决策工况,对感知精度、决策智能与系统泛化能力提出更高要求。
在城市NOA推进过程中,高精地图鲜度不足、覆盖受限、成本高昂等问题,成为核心瓶颈。为突破此限制,主流技术路线正在从依赖地图的规则驱动方案,全面转向端到端模型驱动 + 自主环境建图 + 多模态策略融合的新范式。
技术架构上,感知模块经历了从前向2D视角 → BEV建图 → Occupancy Network建模的迭代,决策控制模块也正由传统rule-based状态机,向基于神经网络的端到端行为预测发展。2025年起,VLM(视觉语言模型)和VLA(Vision-Language-Action)架构逐步上车,赋予系统语义理解与策略推理能力,成为当前算法演进的前沿方向。
本报告将围绕特斯拉、小鹏、理想、蔚来等具备自研能力的头部品牌,梳理其城市NOA技术路线演进路径,结合软硬件系统方案与市场落地节奏,探讨中国品牌如何在“从BEV到VLA”的产业跃迁中建立领先优势。
- 目标用户与使用场景
L2/L2+辅助驾驶系统主要面向具备一定驾驶经验、希望在日常通勤或长途驾驶中降低疲劳、提升安全性的新能源车主及购车潜在用户。
这类用户普遍关注两个关键问题:
各品牌城市NOA在不同城市、路况下的表现差异;
智驾能力与整车价格之间的性价比。
智能驾驶的核心价值在于:在用户监管下,系统能够预判潜在风险、辅助完成复杂驾驶动作,从而减轻认知负担、降低事故风险。尤其在城市NOA场景中,系统需完成红绿灯识别、路口博弈、避让行人、自主换道等行为,对系统泛化能力、策略鲁棒性和人机交互体验提出更高要求。
因此,城市NOA不仅是“功能拓展”,更代表了整车系统智能化水平的“天花板”。
- 竞品分析
本篇章节主要对于特斯拉,以蔚来理想小鹏为代表的头部企业在“城市导航辅助驾驶功能”的进展上进行对比分析,除此之外还包括,硬件系统方案,软件算法,功能配置,交互逻辑,运营方案,亮点场景等对比。
3.1 调研洞察摘要
城市NOA的落地,标志着行业正从规则驱动向数据驱动、从模块化架构向端到端大模型架构转变。以下趋势尤为明显:
技术架构趋同: 特斯拉、小鹏、蔚来等主流厂商均采用BEV+Transformer+Occupancy Network感知结构,逐步引入端到端神经网络控制器替代传统状态机,提升整体智驾稳定性。
算力平台升级: 主流平台从原先144TOPS提升至500–1000TOPS以上,大算力平台成为支持端到端大模型部署的基础设施。
数据闭环能力强化: 具备自动采集、筛选、标注、仿真重建与在线训练能力的“数据-模型-闭环”体系,成为城市NOA性能提升的核心引擎。
用户体验导向增强: 城市NOA正加速从试点区域向全国多城落地,主机厂纷纷围绕“全国都能开、用户真愿用”目标,推动功能迭代与大模型泛化能力提升。
结论:在城市NOA成为新一代智能驾驶标配的背景下,能否构建“低成本、高泛化、大闭环”的自研体系,将成为厂商能否突围的核心分水岭。
3.2 技术方案演进与“去高精地图化”
高速NOA因场景结构稳定,长期采用规则驱动+高精地图方式实现;而城市NOA因存在海量动态变量与非结构化场景,传统Rule-based方案难以覆盖,技术路线普遍演进为以下三个阶段:
基于高精地图的三段式结构: 感知–规划–控制,依赖静态地图与有限状态机;
BEV+Transformer感知融合结构: 引入Occupancy Network构建3D空间占据图,提升遮挡处理与障碍识别能力;
端到端 + 多模态语义推理架构(VLA): 引入视觉语言模型、扩散策略网络、博弈推理模块等,实现感知–理解–决策一体化。
“去高精地图化”已成为城市NOA发展的行业共识,各家方案通过Occupancy Network、弱地图辅助、分布式建图等方式逐步替代静态地图依赖,以提升系统泛化能力与落地效率。
3.2.1 特斯拉技术演进:
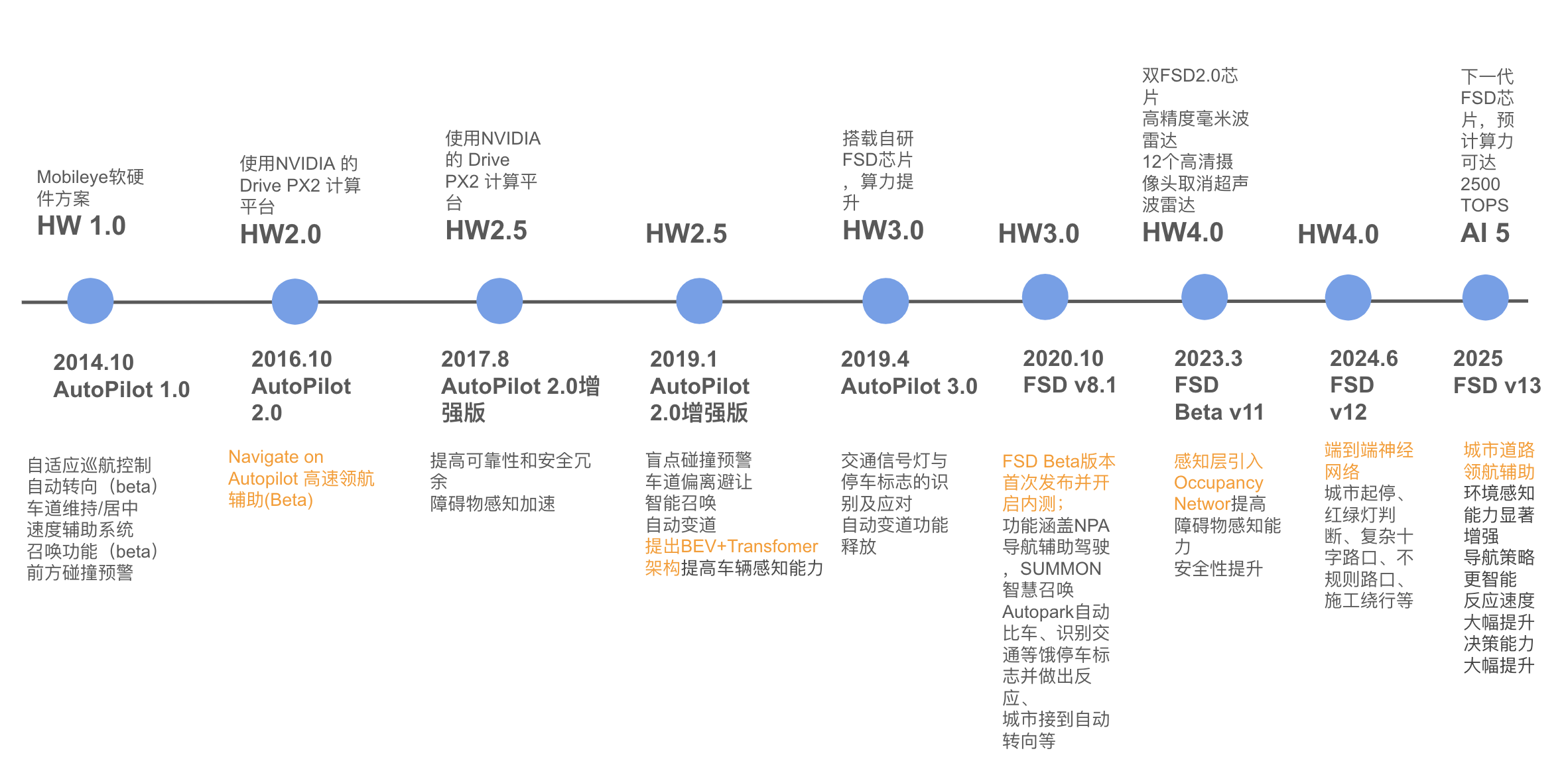
自2014年发布AutoPilot 1.0以来,特斯拉持续引领辅助驾驶从规则驱动走向数据驱动、再走向端到端神经控制的范式演进。
HW1.0 + Mobileye平台(2014–2016): 初代AutoPilot基于Mobileye方案,支持基本的巡航与车道保持功能,但受限于单摄像头配置与规则逻辑,系统泛化能力有限。
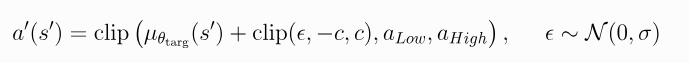 目标策略平滑本质上充当了算法的正则化器(正则化是一组用于减少机器学习模型中过拟合的方法。正则化会用训练准确性的边际下降来换取泛化性的提高。 正则化包含一系列用于纠正机器学习模型过拟合问题的方法。)
它解决了DDPG中可能出现的一种特殊故障模式:如果Q函数逼近器针对某些动作产生了错误的尖峰,策略就会迅速利用改封至,从而导致脆弱或错误的行为。
这种情况可以通过平滑类似动作的Q函数来避免,
而这正是目标策略平滑的设计初衷。
目标策略平滑本质上充当了算法的正则化器(正则化是一组用于减少机器学习模型中过拟合的方法。正则化会用训练准确性的边际下降来换取泛化性的提高。 正则化包含一系列用于纠正机器学习模型过拟合问题的方法。)
它解决了DDPG中可能出现的一种特殊故障模式:如果Q函数逼近器针对某些动作产生了错误的尖峰,策略就会迅速利用改封至,从而导致脆弱或错误的行为。
这种情况可以通过平滑类似动作的Q函数来避免,
而这正是目标策略平滑的设计初衷。