在这个混合路径规划系统中,DRL 策略负责接管那些局部空间极端受限、传统 MPC 难以生效的区域,特别是“狭窄通道(narrow passage)”问题。为此,我们构建了一个专门应对该类场景的 DRL 策略,并通过 TD3 或 DDPG 算法进行训练。
1. 使用的算法与损失函数
我们使用 TD3 或 DDPG 算法,分别训练策略网络(Actor)和价值网络(Critic)。
DDPG
DDPG 有时能够实现出色的性能,但它在超参数和其他类型的调优方面往往很脆弱。DDPG 的一个常见故障模式是,学习到的 Q 函数开始大幅高估 Q 值,从而导致策略破坏,因为它利用了 Q 函数中的误差。
TD3
td3 在DDPG基础上做到了三个技巧的更新,解决DDPG Q值过高的问题
-
技巧1: 裁剪双Q学习 TD3学习两个Q函数 而不是一个(因此称为twin),并使用两个Q值比较小的一个作为bellman误差损失函数中的目标
-
技巧2: “延迟”策略更新 TD3 更新策略和目标网络的频率低于Q函数,本文建议没更新两次Q函数就进行依次策略更新
-
技巧2: 目标策略平滑 TD3为目标动作添加了噪声,通过平滑动作中的Q的变化,使策略更难利用Q函数误差 这三个技巧可以显著提高baseline DDPG 的性能
-
TD3 是一种off-policy algorithm
-
TD3 只能用于具有连续动作空间的环境
-
TD3 的Spinning up实现不支持并行化
关键方程式: TD3通过 均方bellman误差最小化的同时 学习两个Q函数Q_phi_1和Q_phi_2, 其方式于DDPG学习单个Q函数的方式几乎相同, 为了准确展示TD3的实现方式, 以及它与普通DDPG的区别,我们将从损失函数的最内层向外进行讲解。
-
第一:目标策略平滑 用于构成Q学习目标的动作 基于目标策略/mu_theta_targ , 但在动作的每个维度上添加了截断噪声。添加阶段噪声后,目标动作将被阶段, 使其位于有效动作范围内(所有有效动作,都满足alpha_low <= alpha <= alpha_high)。因此,目标动作如下:
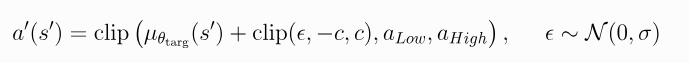 目标策略平滑本质上充当了算法的正则化器(正则化是一组用于减少机器学习模型中过拟合的方法。正则化会用训练准确性的边际下降来换取泛化性的提高。 正则化包含一系列用于纠正机器学习模型过拟合问题的方法。)
它解决了DDPG中可能出现的一种特殊故障模式:如果Q函数逼近器针对某些动作产生了错误的尖峰,策略就会迅速利用改封至,从而导致脆弱或错误的行为。
这种情况可以通过平滑类似动作的Q函数来避免,
而这正是目标策略平滑的设计初衷。
目标策略平滑本质上充当了算法的正则化器(正则化是一组用于减少机器学习模型中过拟合的方法。正则化会用训练准确性的边际下降来换取泛化性的提高。 正则化包含一系列用于纠正机器学习模型过拟合问题的方法。)
它解决了DDPG中可能出现的一种特殊故障模式:如果Q函数逼近器针对某些动作产生了错误的尖峰,策略就会迅速利用改封至,从而导致脆弱或错误的行为。
这种情况可以通过平滑类似动作的Q函数来避免,
而这正是目标策略平滑的设计初衷。 -
第二,裁剪双Q学习 两个Q函数都是用同一个目标,该目标使用两个Q函数中目标值较小的哪个来计算:
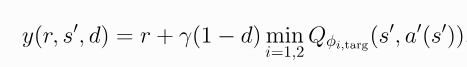
然后通过回归这个目标来学习:
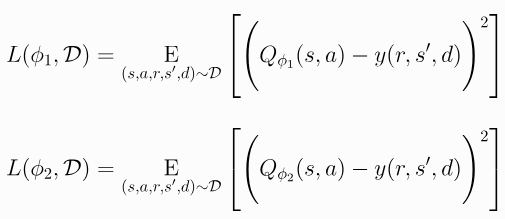
使用较小的Q值作为目标,并想该值回归,有助于避免Q函数的高估
该策略仅通过最大化来学习Q_phi_1:
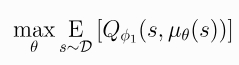
这与DDPG几乎没有变化,然而在TD3中策略的更新频率低于Q函数,这有助于一直DDPG中由于策略更新改变目标而通常出现的波动性。
TD3以离策略(off-policy)的方式训练确定性策略。由于该策略是确定性的,如果agent进行离策略探索,一开始他可能不会尝试足够多的动作来找到有用的学习信号.为了提高TD3策略的探索效果,我们在训练时为其动作添加了噪声,通常是不相干的均值为零的高斯噪声。为了便于获得更高质量的训练数据,可以在训练过程中降低噪声的规模(在现实中不会这么做并且始终保持噪声规模不变)
TD3实现在训练开始时使用了一种技巧来改进探索。在开始时,对于固定数量的步数(使用start_steps关键字参数设置),agents会采取从有效动作的均匀随机分补中采样的动作。之后,它将回复正常的TD3探索。
Critic 损失函数(均方误差 MSE):
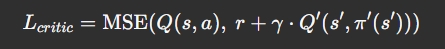
- Q:当前 Critic 网络,输入(s_t, a_t),输出Q(s_t,a_t; theta^Q),估计当前状态-动作对的预期累积回报
- Q’:目标 Critic 网络(延迟同步)
- π’:目标策略网络 给出动作
或者写为: L = E[(Q(s_t, a_t) - y_t )^2]
- y_t = r_t + γ * Q’(s_{t+1}, a’) 目标值
- a’ = π’(s_{t+1})
critic网络训练过程 就是通过这个MSE 损失函数 让当前预测值逐渐靠近目标值
critic网络的作用是接收 (s_t,a_t) 对,输出 Q 值
Q’的输入是s_(t+1) 和动作a’ , 这个动作不是任意选的,而是 a’ = π’(s_{t+1} ) 由**目标 Actor 网络 π’**生成的
所以 π’ 的作用是: 生成下一个状态s_{t+1} 下的动作a' 用于构建目标critic网络(Q’)的输入(s_{t+1} ,a’)
为什么不使用当前策略π? 为了稳定训练: 目标网络π’ Q’ 都是延迟更新的副本,能减少训练不稳定 如果用当前策略π, 每一步都在变化,计算目标y_t 会更抖动,更难收敛
(s_t, a_t, r_t, s_{t+1})
│
↓
Critic(Q) → 输出 Q(s_t, a_t)
当前估计的 Q 值│ π'(s_{t+1})
↓ ↓ π'在s_{t+1}时刻提供动作a' , 用于计算Q’(s_{t+1}, a')
计算MSE Loss ←—————— 计算出目标值[r_t + γ * Q'(s_{t+1}, a')]
Actor 损失函数(最大化期望 Q):
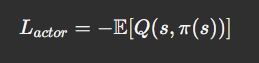
目标是学习在当前状态下能最大化预期 Q 值的动作。 π(s_t):当前 Actor 策略给出的动作 Q(s_t,a_t): critic给该动作打分(累积预期回报)
训练步骤:
- 状态s_t 来自 replay buffer。
- Actor根据状态s_t输出策略动作a_t = π(s_t)
- Critic 对(s_t, a_t)计算Q值
- 用负的Q值当作损失,反向传播更新Actor参数
# s: state batch
action = actor(s) # π(s)
q_value = critic(s, action) # Q(s, π(s))
actor_loss = -q_value.mean() # 损失函数
actor_optimizer.zero_grad()
actor_loss.backward()
actor_optimizer.step()
Actor-Critic
Actor 网络和 Critic 网络会在训练和推理过程中同时使用, Critic输出Q值, Q值用来给Actor网络策略π(s_t)输出的action打分,更新自身策略,目标是让Q值最大, Actor输出的action : a_t =π(s_t) 又被用于critic网络生成Q值
Replay Buffer(经验回放池)是强化学习中的一个 数据存储机制,用于缓存智能体过去的交互数据(s_t, a_t,r_t,s_(t+1)),以便训练时反复利用
2. 网络输入结构
该模型采用 图像 + 几何量 的多模态输入结构:
Actor 网络输入:
- 图像观测(ImageObservation)尺寸为 54×54,经过中心对齐、下采样与归一化处理。
- 几何状态包括:当前速度、角速度、局部路径点信息。
Critic 网络输入:
- 同 Actor 状态部分
- 加入动作维度
[v, ω](线速度与角速度)
模型使用 MultiInputPolicy,支持 dict 类型输入,如:
{
"image": img_tensor,
"speed": v,
"angular_velocity": w,
"ref_path": path_features,
...
}
3. 观测空间组成
来自环境 TrajectoryPlannerEnvironmentImgsRewardExplore 的观测包括:
[
SpeedObservation(),
AngularVelocityObservation(),
ReferencePathSampleObservation(),
ReferencePathCornerObservation(),
ImageObservation(...),
]
这些模块将状态信息封装成统一 dict,用于输入 Actor/Critic 网络。
4. 奖励函数设计
为了专注训练在狭窄通道中安全穿越的行为,奖励函数对路径跟踪和速度控制施加强激励/惩罚,并引入了关键奖励项 NarrowPassageReward:
reward = 0
reward += ReachGoalReward()
reward -= CollisionReward()
reward -= CrossTrackReward()
reward -= ExcessiveSpeedReward()
reward -= AccelerationReward()
reward -= AngularAccelerationReward()
reward += NarrowPassageReward(factor=2.0, width_threshold=1.2)
其中:
NarrowPassageReward:只有当路径宽度低于阈值时启用,鼓励策略在收紧空间内维持稳定动作。- 奖励形状经过归一化、平滑处理,避免训练震荡。
5. 策略训练与部署流程
训练脚本使用 stable-baselines3 接口:
from stable_baselines3 import TD3
model = TD3("MultiInputPolicy", env, verbose=1)
model.learn(total_timesteps=300_000)
model.save("td3_narrow_passage")
部署阶段:
obs = env.reset()
action = model.predict(obs, deterministic=True)
配合 HintSwitcher 控制调用时机,DRL 控制模块仅在障碍过近、MPC 无法规划时介入。
6. 效果与后续优化方向
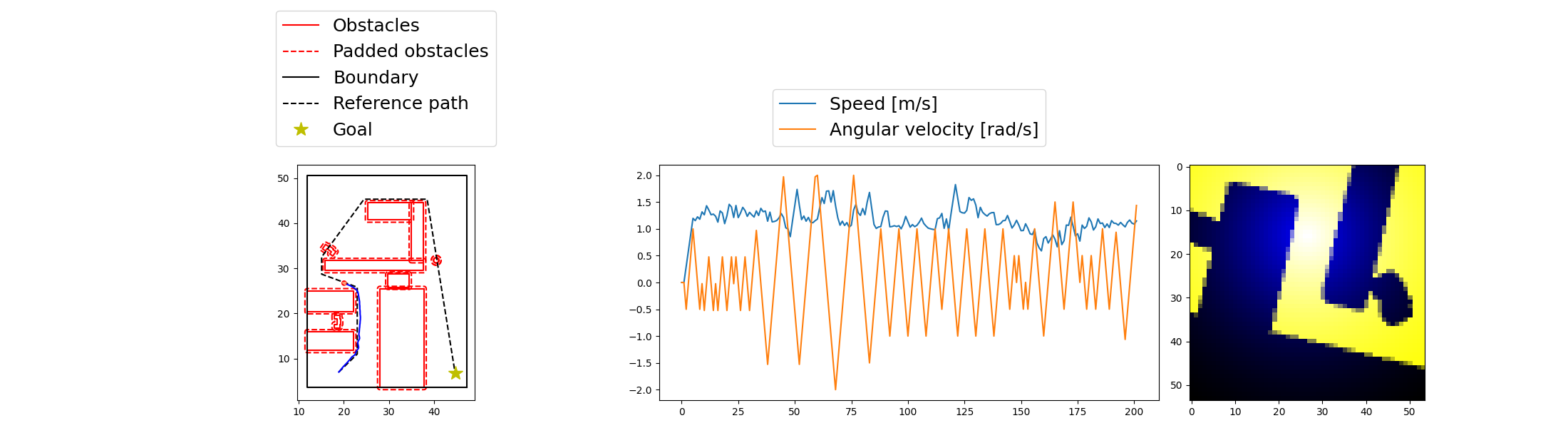
该策略已在多个狭窄通道任务中取得平稳穿越效果,具体表现为:
- 减速主动避障
- 保持路径中心行驶
- 避免局部震荡和动作突变
下一步优化方向包括:
- 多策略集成(curriculum + fine-tune)
- 模拟-实物迁移训练(domain randomization)
- 更精细的 reward shaping(如边界接近惩罚)